Paper notes: Hou et al. (2024)
These are notes for the paper by Hou et al. (2024) titled Decomposing Uncertainty for Large Language Models through Input Clarification Ensembling.
- This paper asks: “How can we effectively quantify and decompose uncertainty in LLMs?” (between aleatoric and epistemic)
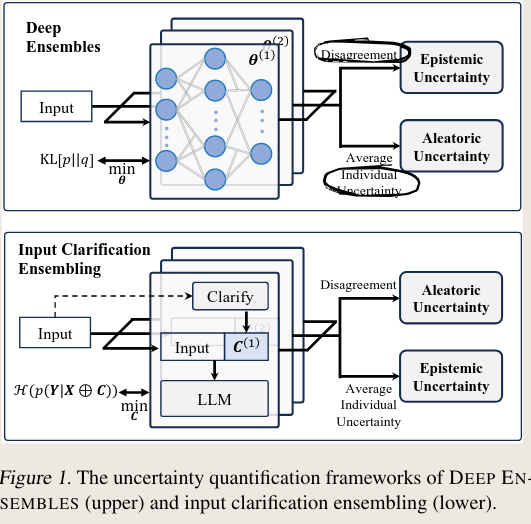
- They propose a method that is analogous to DeepEnsembles. Both the inspiration and their method are illustrated in the Figure:
-
They start by describing DeepEnsembles, and then their own adaptation for LLMs
-
Background definitions:
- X: input, Y: output target
- : parameters of an LLM
- : ground truth distribution. Note that it is a distribution because we are referring to all possible inputs and outputs of a certain task (e.g. the space of questions and answers of a question answering task — huge space!)
- : predicted distribution of Y given X. Again, all possible X and all possible Y. here is fixed (we will soon introduce a distribution over multiple ).
- total entropy of the predicted distribution. This is the overall uncertainty of a model .
- Epistemic uncertainty: how well the LLM approaches the ground truth distribution . Note that training the model (i.e. minimizing a training loss) means fitting to make match . Formally, this means minimizing the KL divergence:
- Aleatoric uncertainty: uncertainty from the data distribution itself. How noisy the data distribution is. Can be quantified with the entropy of the ground-truth distribution
Deep Ensembles
- In the original DeepEnsembles method, we train models (with different initialization values) .
- Denote as the training dataset and as the distribution of model parameters.
- Denote the ensembled distribution of models is .
- Since we are dealing with models, this is the average of the responses.
- And denote the expected (average) entropy among models as
- With models, this is the average entropy among the models.
- Note that this is expression is different from .
- measures the total entropy of the ensemble. measures the average entropy of each individual model.
- From information theory, can use the expression of conditional mutual information to write the expression:
-
Where is the mutual information, which measures the disagreement among the different models.
-
To understand this expression, note that the original definition of the mutual information is defined as:
- Mutual information = (total uncertainty of the ensemble) - (average uncertainty of individual models). With our notation:
- The mutual information quantifies how much information the model parameters contain about the output.
- Lets observe why it measures the disagreement among the models. Suppose we have two models.
- If both are individually very uncertain and yield the same prediction, the ensemble is also uncertain. High ensemble uncertainty minus high average individual uncertainty yields a low , i.e. low disagreement.
- If both are certain, but yield different predictions, the ensemble is uncertain. High ensemble uncertainty minus low average individual uncertainty yields a high , i.e. high disagreement.
- Now, lets (loosely) see why disagreement is a proxy for epistemic uncertainty and why average entropy is a proxy for aleatoric uncertainty.
- Suppose all models perfectly learn the underlying distribution (zero epistemic uncertainty). In this case, they will all be equal and fully agree (zero ). However, they may still be uncertain if there is noise in the data — aleatoric uncertainty, which could only be captured by the average entropy .
- They will be In this case, the models will agree more (low disagreement)If the models agree more, this means they have similarly captured the underlying distribution.
- For a more rigorous understanding, the paper points to Gal et al. 2016.
-
To sum up, in Equation 2 the first term measures disagreement and is a proxy for epistemic uncertainty, while the second term measures the average individual uncertainty and is a proxy for aleatoric uncertainty.
-
Since training slightly different LLMs is too expensive, they add variability in the input by concatenating clarifications to the ambiguous or underspecified input.
Attempt with in-context learning
Following the idea of DeepEnsembles They first try to “produce different models” by using different in-context examples when prompting. They do not observe a difference in uncertainty when comparing ambiguous questions to unambiguous questions. Therefore, this method did not work.
Input clarification ensembling
- While DeepEnsembles produce different models that aim to minimize epistemic uncertainty, they propose a method (input clarification ensembling) that ensembles different inputs to minimize aleatoric uncertainty.
-
Generate clarifications for each input . Concatenate ( ).
- Denote the distribution of inputs as
-
Ensemble: define the ensemble of predictions:
- In simmetry with DeepEnsembles, they propose to decompose the uncertainty of the ensemble:
-
They claim that the first term (mutual information) approximates the aleatoric uncertainty caused by ambiguity. And that the second term (average entropy given each clarification) measures the model’s uncertainty across clarified versions of the imput — approximates epistemic uncertainty.
-
Maybe limitation: aleatoric uncertainty here is limited to instruction ambiguity and question ambiguity
Experiments
- Can the UQ framework quantify total uncertainty correctly?
- Mistake detection experiment
- Can the UQ framework decompose the uncertainty correctly?
- Ambiguity detection
- Monotonicity check
- Recall of correct answers
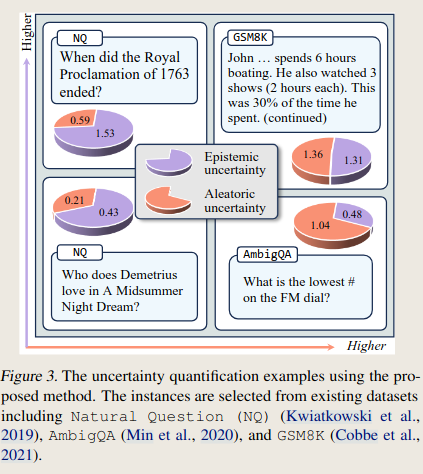
- Data: Natural Question (NQ), AmbigQA and GSM8K (factoid QA and mathematical reasoning)
- Comparisons: Semantic Entropy and Ask4Conf
- They report positive outcomes