Paper notes: Ye et al. (2024)
These are notes for the paper by Ye et al. (2024) titled Benchmarking LLMs via Uncertainty Quantification.
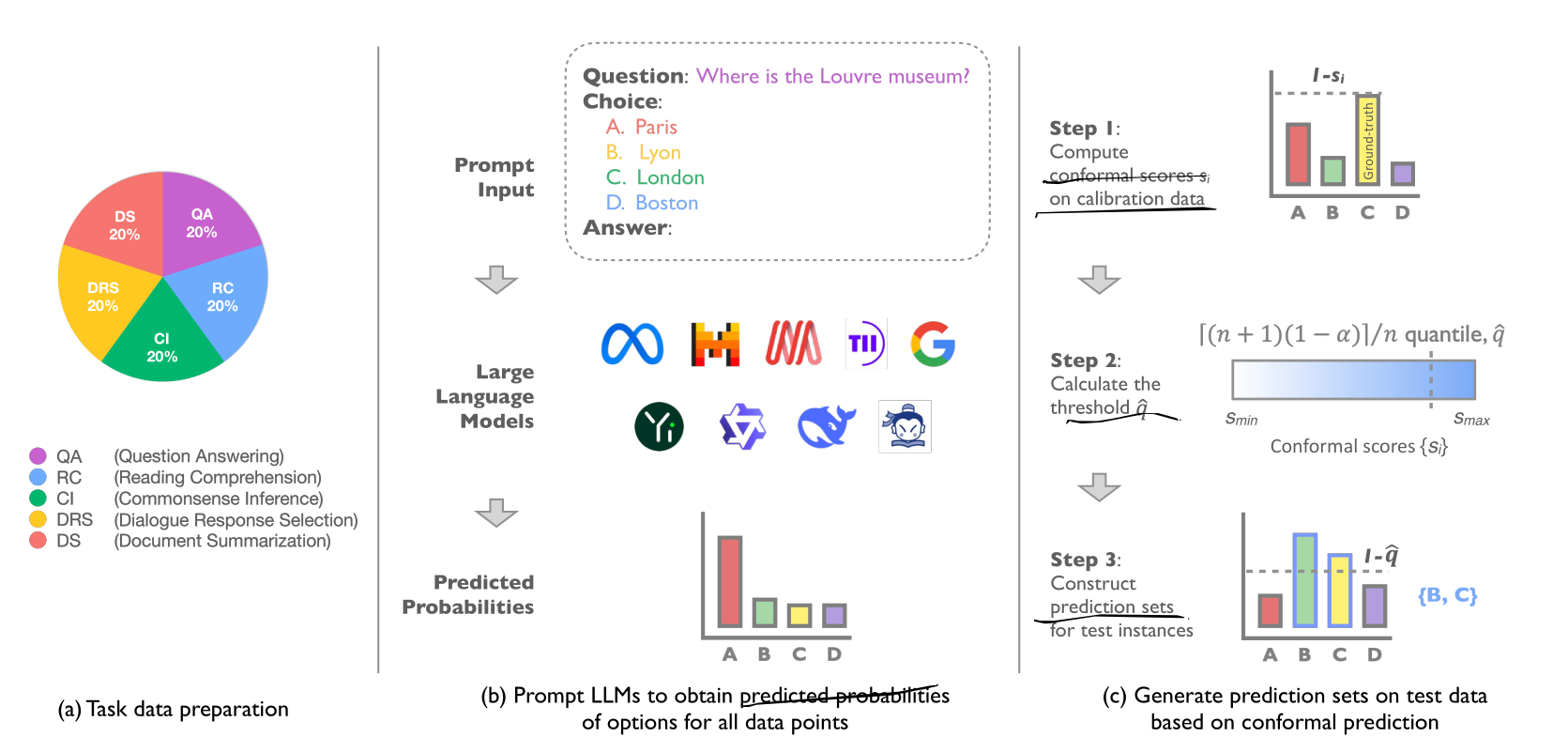
- They benchmark LLMs wrt uncertainty, using the logits of the output and Conformal Predictions, given a multiple choice task
- They argue that CP is better for measuring uncertainty. Rather than:
- Confidence based methods — sensitive to poor calibration
- Bayesian methods — high computational complexity
- Ensemble methods — ?
- Tasks: QA, reading comprehension, common sense inference, dialog response, document summarization.
- They use multiple-choice tasks, with 6 options, two being “none of the above” and “i don’t know”.
- Datasets: MMLU, CosmosQA, HellaSwag, HaluDial, HaluSum.
- They apply a conformal prediction framework to measure uncertainty.
- To get a score, they first compute the softmax of the logits of the letters A to F of the multiple choice answer. Then, they compute the average between the LAC score and the APS score, using the output probability of the correct answer.
- Finally, they report set size as the uncertainty evaluation metric. As well as coverage rate.
- They compare their score with the perplexity metric (computed from entropy).
- They consider many LLMs in their analysis.
Free form text generation
- There is one section where they attempt to apply CP to free-form text (6.8). In it, they generate 20 answers for each question from the TriviaQA dataset, and assume it as the selection space (possible space). They use exact match to verify the accuracy of the generated answer.
- They use the perplexity metric as conformal score.
- In this scenario coverage rate cannot be guaranteed.
- How can we robustly use CP for free form text?
— maybe we should attempt using CP techniques?
NOTE
Good:
- Different tasks
- Conformal predictions — formal framework
Limitations:
- Entangled sources of uncertainty
- Focuses on multiple choice questions
- CP methods: