Paper notes: Tomov et al. (2024)
Summary
- Motivation: Accurate uncertainty quantification in LLMs is crucial for trustworthy deployments.
- Research Gap: Existing UQ methods are benchmarked against datasets without aleatoric uncertainty (AU). (Devic et al., 2025)
- Contributions:
- Theory
- They show why current UQ methods work in absence of AU
- They show why current UQ methods break down in the presence of AU
- Empirical
- They produce MAQA* and AmbigQA* (datasets with unresolvable ambiguity)
- They empirically validate their theoretical claims
- Theory

Aren’t there ambiguity benchmarks?
- There are ambiguity benchmarks (E.g. AmbigSci-QA, MAQA, etc). However, these are focused on resolving the ambiguity and providing clarifications, while Tomov2025 measures uncertainty under unresolvable ambiguity.
- Furthermore, some work uses the variation of clarifications to measure aleatoric uncertainty.
Dataset details

- The datasets are adaptations of previous QA datasets with ambiguity.
- The questions have multiple correct answers. They modify the questions to ask for a single answer. Therefore, its ambiguity cannot be resolved.
- They compute the ground-truth probability of each answer by counting co-references in a proxy corpus (Wikipedia)
Theoretical results
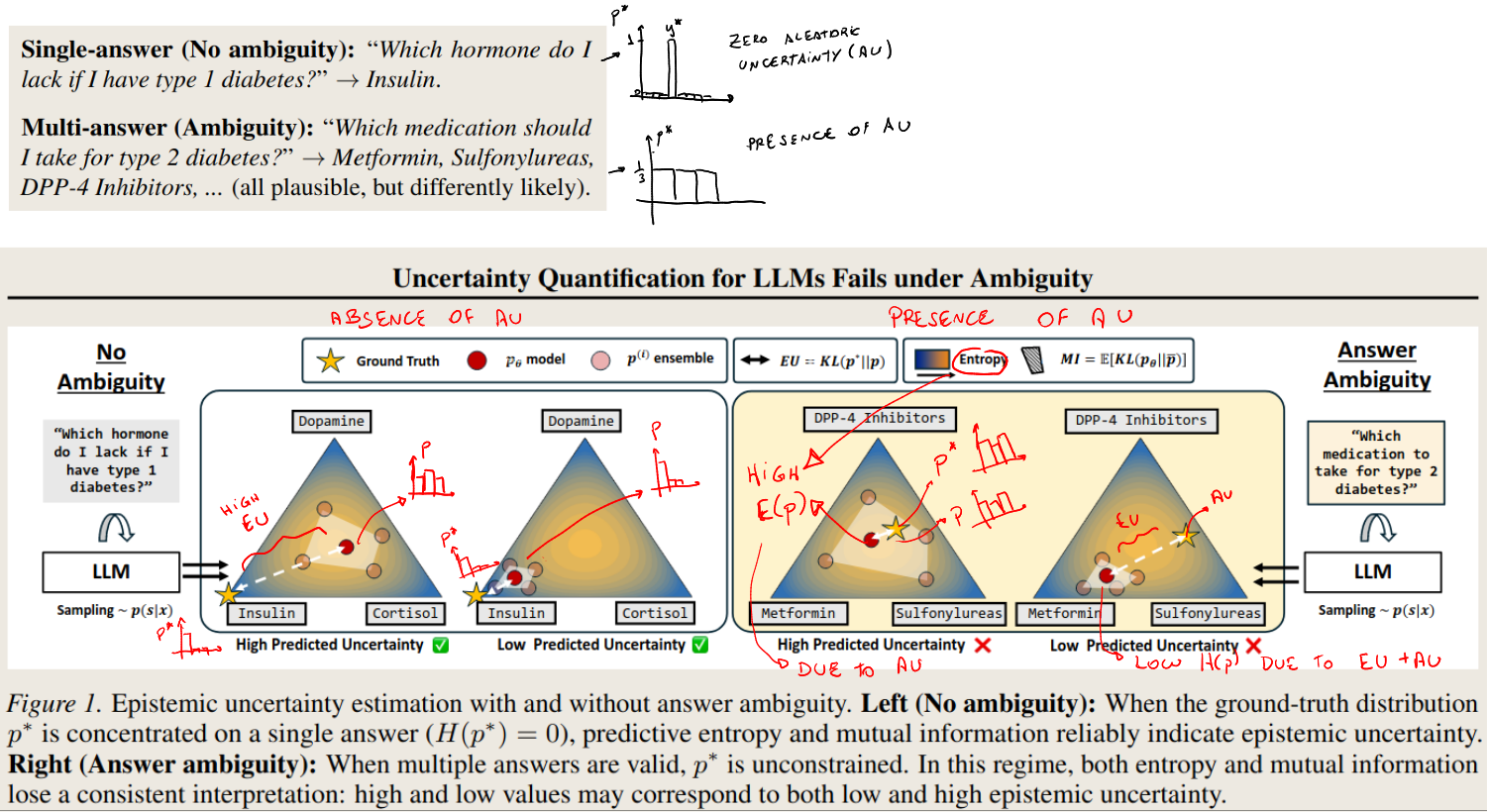
- Preliminaries: how they decompose total uncertainty

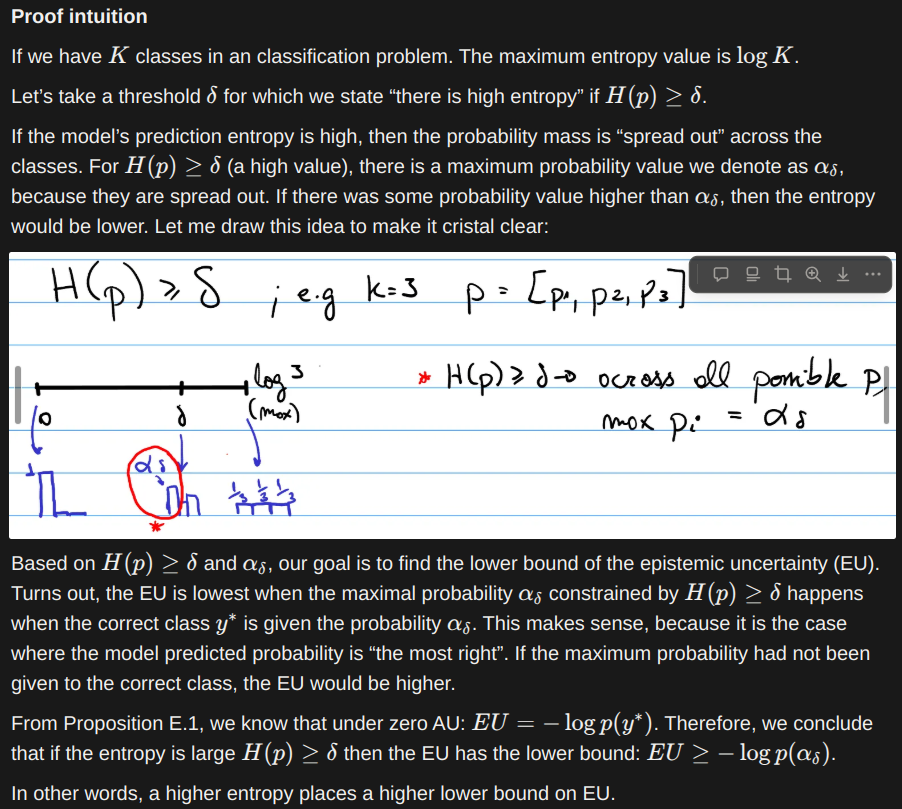
- Theoretical result 1: Assuming aleatoric entropy is zero, a model with high predictive entropy necessarily has high epistemic uncertainty.
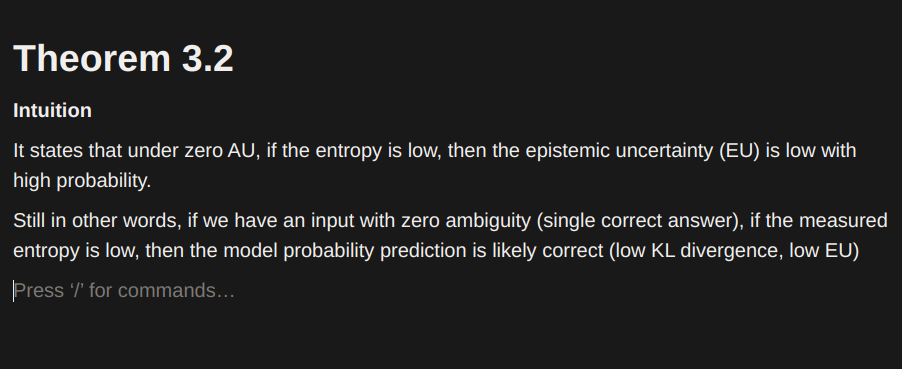
- Theoretical result 2: Assuming aleatoric entropy is zero, a model with low predictive entropy has low epistemic uncertainty with high probability
- The two results above explain why current methods of UQ measurement work. They are estimating an entropy that is (positively) correlated with epistemic uncertainty.
- They prove this result for both consistency based (entropy) methods and ensemble based methods
- They argue that under the presence of aleatoric uncertainty, this correlation cannot be guaranteed.


- Theoretical result 3: It is impossible to disentangle EU from AU using just the model’s prediction.

Experiments
Obtaining the True Distribution p*

- They use the English Wikipedia Wikimedia Enterprise as proxy for the pre-training corpus.
- To estimate the frequency of each answer, they use co-occurrence frequency.
- First, they extract keywords from each pair of question-answers (using an LLM and a prompt).
- Then, they stem the keywords and search for co-ocurrences of keywords plus each candidate answer in the corpus [add prompt print]
- They use an entailment model to verify the factual occurrence of each candidate co-occurance (Table 9)
- They further validate the counts with different corpus and strategy variations. The verify that the distributions among different corpus and strategies are aligned (with the Jensen-Shannon divergence)
Output:
- For each question, we have a set of plausible answers and the frequency of each one. (p* for each question)
Experimental Setup
UQ estimators
- Consistency:
- Semantic Entropy (SE)
- Maximum Sentence Probability (MSP)
- Shifting Attention to Relevance (SAR)
- Internal representation:
- Residual stream activation at layer l (?) for the final input token. Trains linear probes and 2-layer MLPs with squared error loss to predict Epistemic Uncertainty (EU)
- Ensembles:
- LLaMA + Gemma + Qwen -> estimate mutual information
Datasets
- Zero Aleatoric Uncertainty (AU): TriviaQA
- With AU: proposed datasets (MAQA* and AmbigQA*)
Models
- Lamma3.1 8b; Gemma3 12B; Quen2.5 14B
Metrics
- Measurement goal: How well the EU represents the true EU according to Equation 1.
- Metric: concordance statistic. AUC_c.
- Measures the probability that an estimator correctly ranks a sample with higher EU above a sample with lower true EU.
- Can be interpreted as AUC-ROC.
Results
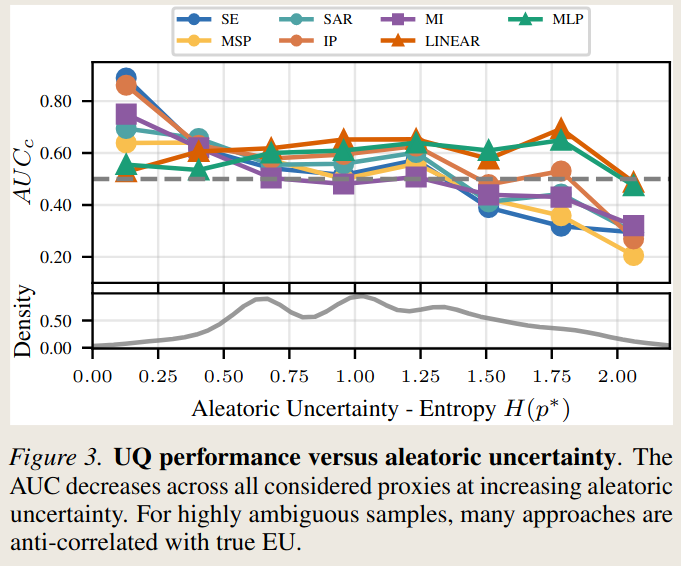
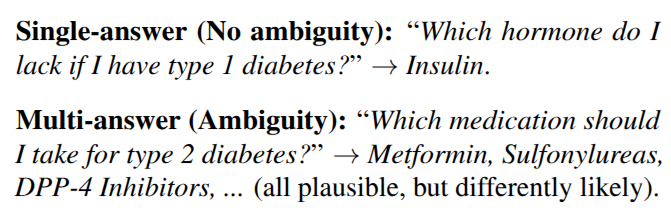
- Estimators perform well in absence of aleatoric uncertainty (TriviaQA).
- Exception: linear probes
- Performance collapses when introducing aleatoric uncertainty (MAQA*, AmbigQA*)
Related Work
UQ for LLMs
Interesting remark: “Prior work has shown that hidden representations can encode factual correctedness, but has not examined settings with intrinsic ambiguity” (Li et al 2023; Chen et al 2024; Orgad et al 2025).
Ambiguity in QA
Here they mention MAQA (Yang et al. 2025) as the sole dataset to consider QA where ambiguity cannot be solved through clarification. They argue that their experimental approach is very different from Yang’s, since Yang generates all valid answers for a question, while in this paper they ask for only one. Notably, Yang focuses on quantifying LLM uncertainty due to data uncertainty.
Discussion
Limitations
- Quantifies p* as factual occurrences in wikipedia.
- Theoretical analysis applies only to consistency and ensemble based estimators (not for internal representations).
- Frames UQ as classification problem
- They do not provide an uncertainty estimator (of epistemic uncertainty) that is robust to aleatoric uncertainty
- The defined task may not be useful downstream. I think this is not a natural task. Whenever we ask a question that allows multiple answers (to an LLM), we expect to get all correct answers.
Contributions
- Provide formal understanding of relationship between UQ in LLMs and ambiguity
- In absence of aleatoric uncertainty: derive correlation between uncertainty proxies and true epistemic uncertainty
- In presence of aleatoric: show (theoretically and empirically) that current estimators are ineffective
- Dataset for UQ under ambiguity
- Also, their ground truth allows to measure the aleatoric uncertainty directly (entropy on p*)
Future work
- They hope to see active modelling of uncertainty during model training
Parsing the proofs
(wrote this in notion to use equations, pasting picture here)


Where to go from here?
- More realistic task – From Calibration to Collaboration: LLM Uncertainty Quantification Should Be More Human-Centered
- Develop UQ method that is robust to aleatoric uncertainty